Sending Data through Aether Connect
In this section, we discuss the various components of Aether Connect and how data flows through the system. It is not entirely necessary for you to understand all the details, but it is helpful to know what is happening with your data.
Assuming you followed the previous section and used ODK to submit data to Gather, you should now have one or more filled in surveys stored in Gather’s internal postgreSQL database. These submissions are stored as JSON documents and are never changed. Gather always maintains a copy of the data exactly as submitted.
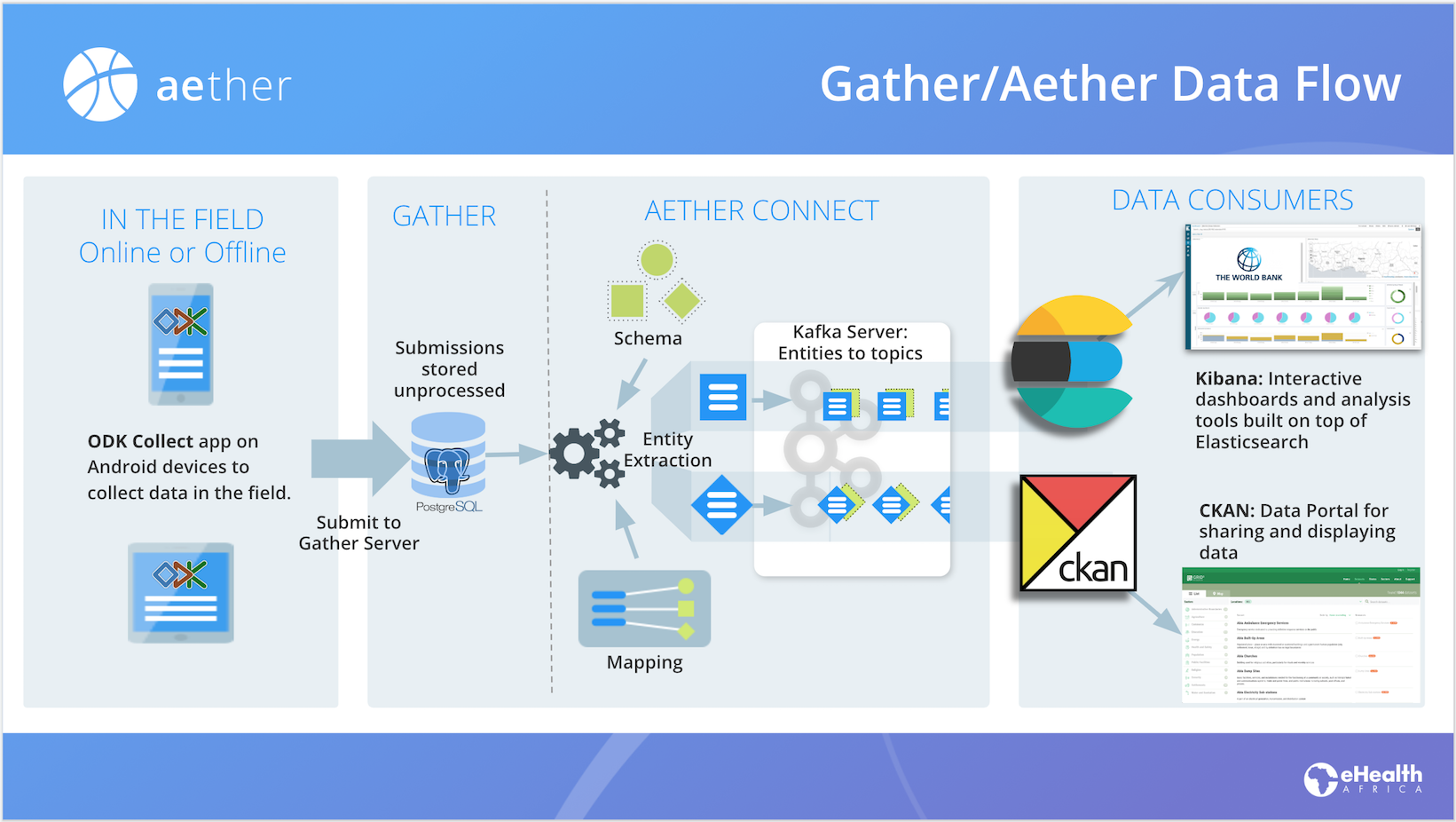
Mapping
The Aether kernel contains services for converting the structure of JSON documents from one format to another or from one document to several related ones. We call this mapping. A common use case for mapping is to normalize your data. For example, the household data in a census form will have information about the physical location, facts about the structure and the names, ages and sex of people living within. Aether’s mapping can convert this data into 3 separate sets of documents: Location, Household and Person all linked together with globally unique ids.
Schema
In order for down-stream systems to understand the data we are sending, the Aether kernel has services that help define the structure of the data being sent. We call this schema. Schemas act like a contract between Aether and the outside world.
Entities
Aether combines the incoming data with a mapping transformation and schema definitions to generate output documents that we call entities, for lack of a better term. We call this process entity extraction. Entities are packaged up using a data serialization system called Avro which provides for the schema and a format for data delivery. The packaged entities are sent to a Kafka streaming data pipeline as topics and messages. Downstream systems subscribe to topics and message delivery is guaranteed by Kafka.
How ODK and Gather uses all this
- An ODK form developer creates an XForm or XLSForm to describe the data and user experience for a survey.
- They upload that form to Gather
- Gather reads the form and uses the definition to generate a schema and a default mapping.
- Gather serves that form to the Android device when requested by the ODK Collect app
- ODK user performs a survey which sends the form data as a submission to Gather
- Submissions are stored and a copy of the data is sent to Aether for entity extraction
- Aether combines the data with the schema definition and mapping to generate an entity or entities which are also saved.
- An Aether process called the producer detects the new entities and packages them up as Avro and passes them to Kafka for distribution.
- External systems can use the Kafka API to read the data as it enters the Kafka queue. For applications that don’t natively use Kafka, there are Aether Consumers that pull messages from the Kafka queue and pushes them into applications like CKAN or Elasticsearch.
Setting Up Aether Connect
To start Aether Connect, run the following scripts/start.sh command from the aether-bootstrap folder:
./scripts/start.sh
This will start the distributed streaming platform Kafka, Zookeeper (which manages Kafka) and the Aether Producer (which handles communication between Aether and Kafka).
Recap
Okay, so that was a lot of documentation to read before doing one little command. And that one little command was very anticlimactic. As mentioned many times, Gather is an application built on top of Aether. As such, Gather uses Aether magic behind the scenes but as a Gather user, there is not much “Aether” you are exposed to. The next section is a lot more visual as you get to see the data come back out of the system.
You are free to pick either CKAN or Elasticsearch/Kibana for the next steps. If you want to do both, that is fine too as they will work together.